
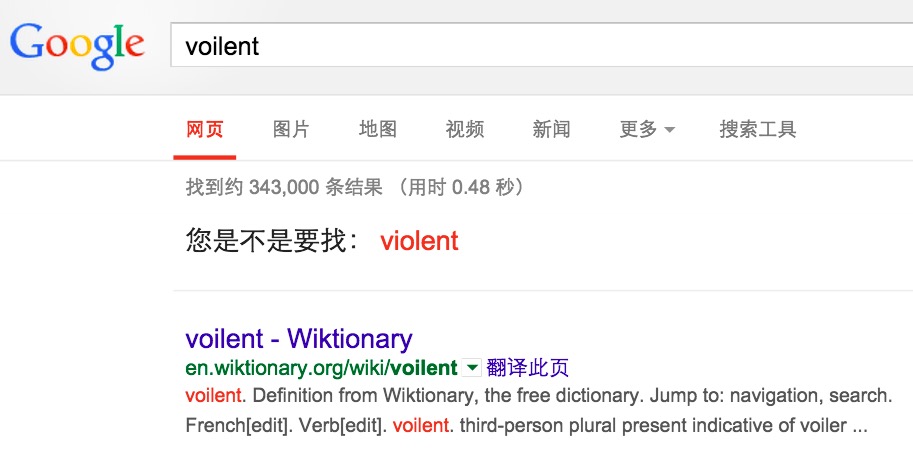
ељУжИСдїђеЬ®CollinsиѓНеЕЄдЄ≠иЊУеЕ•вАЬvoilentвАЭзЪДжЧґеАЩпЉМдЉЪжЬЙе¶ВдЄЛжПРз§ЇпЉЪ

ељУжИСдїђеЬ®GoogleдЄ≠жРЬ糥вАЬvoilentвАЭзЪДжЧґеАЩпЉМдєЯдЉЪжЬЙе¶ВдЄЛжПРз§ЇпЉЪ
CollinsеТМGoogleжШѓе¶ВдљХеБЪеИ∞зЪДеСҐпЉЯеЃГжШѓжАОдєИзЯ•йБУжИСдїђжККiеТМoзЪДдљНзљЃеЉДеПНдЇЖеСҐпЉЯ
ељУжИСдїђиЊУеЕ•дЄАдЄ™иѓНпЉМиАМињЩдЄ™иѓНдЄНе≠ШеЬ®дЇОGoogleзЪДеАТжОТ糥еЉХжИЦиАЕCollinsзЪДиѓНеЕЄдЄ≠жЧґпЉМжИСдїђе∞±еПѓдї•еБЗиЃЊзФ®жИЈиЊУеЕ•еПѓиГљжЬЙиѓѓпЉМжО•зЭАжИСдїђйАЪињЗзЃЧж≥ХжЙЊеЗЇдЄАдЄ™еТМзФ®жИЈзЪДиЊУеЕ•жЬАзЫЄдЉЉзЪДиѓНжО®иНРзїЩзФ®жИЈпЉМињЩдЄ™жЙЊеЗЇеТМзФ®жИЈиЊУеЕ•жЬАзЫЄдЉЉзЪДиѓНзЪДзЃЧж≥ХжЬЙеЊИе§ЪзІНпЉМжЬАеЄЄзФ®зЪДжЬЙзЉЦиЊСиЈЭз¶їзЃЧж≥ХпЉИEdit DistanceпЉЙпЉМеЫ†дЄЇињЩдЄ™зЃЧж≥ХжШѓдњДзљЧжЦѓзІСе≠¶еЃґVladimir LevenshteinеЬ®1965еєіжПРеЗЇзЪДпЉМжЙАдї•зЉЦиЊСиЈЭз¶їпЉИEdit DistanceпЉЙеПИеПЂеБЪLevenshteinиЈЭз¶їгАВ
зЉЦиЊСиЈЭз¶їзЃЧж≥ХжШѓжМЗдЄ§дЄ™е≠ЧдЄ≤дєЛйЧіпЉМзФ±дЄАдЄ™иљђжИРеП¶дЄАдЄ™жЙАйЬАзЪДжЬАе∞СзЉЦиЊСжУНдљЬжђ°жХ∞пЉМеЕБиЃЄзЪДзЉЦиЊСжУНдљЬеМЕжЛђе∞ЖдЄАдЄ™е≠Чзђ¶жЫњжНҐжИРеП¶дЄАдЄ™е≠Чзђ¶пЉМеҐЮеК†дЄАдЄ™е≠Чзђ¶пЉМеИ†йЩ§дЄАдЄ™е≠Чзђ¶гАВ
дЊЛе¶Ве∞ЖkittenиљђжИРsittingпЉЪ¬†
sitten пЉИkвЖТsпЉЙе∞ЖдЄАдЄ™е≠Чзђ¶kжЫњжНҐжИРеП¶дЄАдЄ™е≠Чзђ¶s
sittin ¬†пЉИeвЖТiпЉЙ е∞ЖдЄАдЄ™е≠Чзђ¶eжЫњжНҐжИРеП¶дЄАдЄ™е≠Чзђ¶i
sitting пЉИвЖТgпЉЙ еҐЮеК†дЄАдЄ™е≠Чзђ¶g
жЙАдї•зЉЦиЊСиЈЭз¶їдЄЇ3пЉМwordеИЖиѓНжПРдЊЫдЇЖзЉЦиЊСиЈЭз¶їзЃЧж≥ХзЪДJavaдї£з†БеЃЮзО∞пЉМеРМжЧґsuperwordй°єзЫЃдєЯжЉФз§ЇдЇЖзЉЦиЊСиЈЭз¶їзЃЧж≥ХеѓєдЇОеНХиѓНиЃ∞ењЖзЪДиЊЕеК©дљЬзФ®гАВ
 
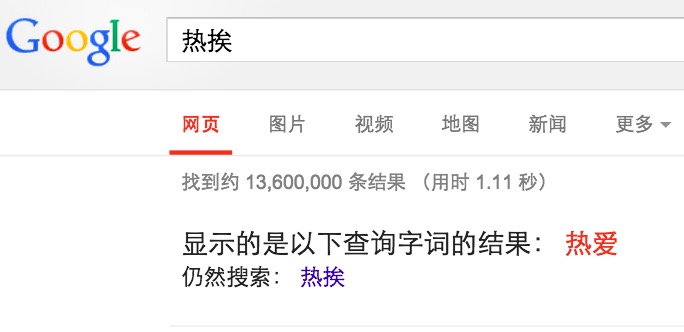
дЄЛйЭҐжИСдїђзЬЛзЬЛдЄ≠жЦЗзЪДжГЕеЖµпЉМељУжИСдїђеЬ®GoogleжРЬ糥вАЬзГ≠жМ®вАЭзЪДжЧґеАЩпЉМGoogleеЬ®еАТжОТ糥еЉХдЄ≠жЙЊдЄНеИ∞вАЬзГ≠жМ®вАЭињЩдЄ™иѓНпЉМдЇОжШѓеЃГзМЬжµЛжИСдїђзЬЯж≠£жГ≥жРЬ糥зЪДжШѓвАЬзГ≠зИ±вАЭпЉМйВ£дєИGoogleжШѓжАОдєИзМЬжµЛеИ∞жИСдїђзЪДжДПеЫЊзЪДеСҐпЉЯ
еЈ•дљЬеОЯзРЖеТМдЄКйЭҐдїЛзїНзЪДиЛ±жЦЗиѓНжѓФиЊГзЫЄдЉЉпЉМеП™жШѓзЃЧж≥ХдЄНдЄАж†ЈпЉМе¶ВжЮЬжККзЉЦиЊСиЈЭз¶їзЃЧж≥ХеЇФзФ®еИ∞ињЩйЗМпЉМжХИжЮЬдЉЪеЊИеЈЃпЉМйВ£дєИжАОдєИеКЮеСҐпЉЯ
иІ£еЖ≥жЦєж≥ХжШѓеИ©зФ®ж±Йиѓ≠зЪДеРМйЯ≥иѓНеОЯзРЖпЉМеЕИжККвАЬзГ≠жМ®вАЭиљђжНҐдЄЇжЛЉйЯ≥вАЬreaiвАЭпЉМзДґеРОжЙЊеЗЇжЙАжЬЙжЛЉйЯ≥дЄЇвАЬreaiвАЭзЪДеПМе≠ЧиѓНпЉМеЬ®жМЙзЕІиѓНзЪДеЗЇзО∞йҐСзОЗеПЦйҐСзОЗжЬАе§ІиАЕвАЬзГ≠зИ±вАЭгАВ
 
жЫіе§ЪиµДжЦЩпЉЪ
How to Write a Spelling CorrectorвАЛ
Using the Web for Language Independent Spellchecking and Autocorrection
 
 
 
 
 



зЫЄеЕ≥жО®иНР
зљСзЂЩзФ®жИЈеѓЖз†БзМЬжµЛеЈ•еЕЈ1.0зЙИ.rar
еЕґдЄ≠зЪДfapai()еЗљжХ∞жЬђдЇЇдєЯжШѓеЬ®зљСдЄКзЬЛеИ∞зЪД,еРОжЭ•иК±дЇЖзВєжЧґйЧіжЙНжККеЃГжРЮеЃМжХідЇЖ,и∞ГиѓХеПѓйАЪињЗ...и¶БзЪДеИЖе§ЪдЇЖ,дЄНе•љжДПжАЭеХ¶
зЉЦеЖЩдЄАдЄ™JavaеЇФзФ®з®ЛеЇПпЉМеЃЮзО∞е¶ВдЄЛеКЯиГљпЉЪ ...зФ®жИЈдїОйФЃзЫШиЊУеЕ•иЗ™еЈ±зЪДзМЬжµЛпЉЫ з®ЛеЇПињФеЫЮжПРз§Їдњ°жБѓпЉМжПРз§Їдњ°жБѓеИЖеИЂжШѓвАЬзМЬе§ІдЇЖвАЭгАБвАЬзМЬе∞ПдЇЖвАЭгАБеТМвАЬзМЬеѓєдЇЖвАЭпЉЫ зФ®жИЈеПѓж†єжНЃжПРз§Їдњ°жБѓеЖНжђ°иЊУеЕ•зМЬжµЛпЉМзЫіеИ∞жПРз§Їдњ°жБѓжШѓвАЬзМЬеѓєдЇЖвАЭгАВ
зљСзЂЩзФ®жИЈеѓЖз†БзМЬжµЛеЈ•еЕЈ
еЬ®жѓПжђ°зМЬжµЛ4дЄ™жХ∞е≠ЧзїДеРИзЪДе∞ЭиѓХзїУжЭЯжЧґпЉМиЃ°зЃЧжЬЇе∞ЖжПРдЊЫеПНй¶Идњ°жБѓпЉМжМЗз§ЇзФ®жИЈжШѓеР¶ж≠£з°ЃзМЬжµЛдЇЖдЄАдЄ™жХ∞е≠ЧпЉМжИЦ/еТМзФ®жИЈжШѓеР¶ж≠£з°ЃзМЬжµЛдЇЖдЄАдЄ™жХ∞е≠ЧеТМжХ∞е≠ЧгАВ зО©еЃґењЕй°їеЬ®10жђ°е∞ЭиѓХдЄ≠赥еЊЧж≠£з°ЃзЪДжХ∞е≠ЧзїДеРИжЙНиÚ赥еЊЧжѓФиµЫгАВ жКАжЬѓйҐЖеЯЯ React JS...
зЉЦз®ЛеЇПпЉМиЃ©иЃ°зЃЧжЬЇжЭ•зМЬжµЛзФ®жИЈвАЬжЪЧиЃ∞вАЭзЪДжЯРеЉ†жЙСеЕЛзЙМпЉЪиЃ°зЃЧжЬЇдїОдЄАеЙѓжЙСеЕЛзЙМпЉИ54еЉ†пЉЙдЄ≠дїїжДПжКљеЗЇ27еЉ†пЉМжСЖжФЊеЬ®дЄНеРМзЪДдЄЙи°МдЄКпЉИжѓПи°М9еЉ†пЉЙпЉМзФ®жИЈвАЬжЪЧиЃ∞вАЭжЯРеЉ†зЇЄзЙМпЉМиАМеРОеСКиѓЙиЃ°зЃЧжЬЇжЙАвАЬжЪЧиЃ∞вАЭзЪДйВ£еЉ†зЇЄзЙМе§ДдЇОеУ™дЄАи°МдЄ≠пЉЫ...
зМЬжХ∞е≠Ч жШѓдЄАжђЊжЄЄжИПпЉМдљњзФ®жИЈжЬЙжЬЇдЉЪзМЬжµЛ1еИ∞20дєЛйЧізЪДж≠£з°ЃжХ∞е≠ЧгАВзФ®жИЈжЬЙ10жђ°е∞ЭиѓХзМЬжµЛж≠£з°ЃзЪДжХ∞е≠ЧгАВ е±ПеєХ
жЈ±еЇ¶е≠¶дє†еѓєдЇОеП£дї§зМЬжµЛзЪДеЇФзФ®пЉМе∞ЖдЇЇеЈ•жЩЇиГљдЄОеП£дї§з†іиІ£зїУеРИиµЈжЭ•пЉМеЇФзФ®жЬАжЦ∞зЃЧж≥ХињЫи°МеП£дї§зМЬжµЛ
AIеЫҐйШЯзОЗеЕИеБЪзЪДе∞ЭиѓХжШѓеЬ®дЄАдЇЫзЙєеЃЪеЬЇжЩѓдЄЛзМЬжµЛзФ®жИЈжДПеЫЊпЉМињЫи°МжДПеЫЊзЫЄеЕ≥жО®иНРпЉМе¶ВдљПйЕТеЇЧзФ®жИЈпЉМеЬ∞йУБдЄКзФ®жИЈз≠ЙпЉМињЩжШѓзЃЧж≥ХеПѓдї•еБЪзЪДдЇЛжГЕпЉМйВ£жµЛиѓХеЬ®ињЩдЄ™ињЗз®ЛдЄ≠еПѓдї•еБЪдЇЫдїАдєИеСҐпЉЯзЃЧж≥Хй™МиѓБзЫЄеѓєжїЮеРОпЉМжЬЙдїАдєИеПѓдї•еЕИи°МзЪДеСҐпЉЯзФ®жИЈжДПеЫЊ...
зїЉеРИжЭ•зЬЛпЉМеЃЮй™МжХИжЮЬеЊЧеИ∞дЇЖеЊИзЪДжПРеНЗпЉЙеЃЮзО∞зїЖиКВиѓ•зЃЧж≥ХзЪДеЃЮзО∞дЄїи¶БеМЕжЛђдЄЙдЄ™йГ®еИЖпЉЪеП£дї§йЫЖйҐДе§ДзРЖгАБеП£дї§йЫЖиЃ≠зїГгАБеП£дї§зМЬжµЛпЉМдљњзЪДзЉЦз®Лиѓ≠дЄЇpython3.7пЉМеЕЈдљУзїЖиКВе¶ВдЄЛжЙАпЉЪеП£дї§
еЯЇдЇОз•ЮзїПзљСзїЬзЪДеЃЪеРСеП£дї§зМЬжµЛз†Фз©ґ.pdf
ињЩжШѓдЄАдЄ™зФ®жИЈеПЛе•љзЪДеЇФзФ®з®ЛеЇПпЉМеПѓдї•иЗ™зФ±еЃЪеИґдї•жї°иґ≥жВ®зЪДйЬАж±ВгАВињЩдЄ™жЄЄжИПзЪДзЫЃзЪДжШѓжПРдЊЫдЄАдЄ™жДЙењЂеТМжЬЙиґ£зЪДдљУй™МгАВељУдљ†еЉАеІЛжЄЄжИПжЧґпЉМдљ†дЉЪеЊЧеИ∞дЄАдЄ™йЪРиЧПзЪДеНХиѓНпЉМиЃ©дљ†йАЪињЗиЊУеЕ•е≠ЧжѓНжЭ•зМЬжµЛгАВжѓПдЄ™йФЩиѓѓзЪДзМЬжµЛйГљдЉЪеѓЉиЗідЄАдЄ™дЇЇзЪДдЄАйГ®еИЖ襀...
ињЩжШѓдЄАдЄ™зФ®жИЈеПЛе•љзЪДеЇФзФ®з®ЛеЇПпЉМеПѓдї•иЗ™зФ±еЃЪеИґдї•жї°иґ≥жВ®зЪДйЬАж±ВгАВж≠§еЇФзФ®з®ЛеЇПзЪДзЫЃзЪДжШѓжПРдЊЫдЄАзІНжЬЙиґ£зЪДжЄЄжИПпЉМжВ®йЬАи¶БзМЬжµЛеП£иҐЛе¶ЦжА™зЪДйЪРиЧПиљЃеїУгАВиѓ•еЇФзФ®з®ЛеЇПињШдљњзФ®дЄАдЄ™ APIпЉМзФ®дЇОиОЈеПЦжИСдїђеЬ®ж≠§з®ЛеЇПдЄ≠дљњзФ®зЪДжЙАжЬЙеП£иҐЛе¶ЦжА™зЪДеЫЊеГПжХ∞жНЃ...
#include const int MIN_NUM=1; const int MAX_NUM=1000; class guessGame { public: void play(); protected: int m_nHi; int m_nLo; int m_nGuess; int m_nHint; void startGame();...
# зМЬжµЛжђ°жХ∞ i = 1 # """е∞ЖuserдЄОcomputerжѓФиЊГпЉМеСКиѓЙuserзМЬе§ІдЇЖињШжШѓзМЬе∞ПдЇЖ""" while user != computer: if user computer and user != 0: user = int(input("дљ†зМЬе§ІдЇЖпЉМеЖНзМЬпЉМгАРе¶ВжЮЬдљ†дЄНжГ≥зМЬдЇЖпЉМиЊУеЕ•0гАС")) if...
йЗЗзФ®ServletеЃЮзО∞зМЬжХ∞жЄЄжИПгАВжЄЄжИПзЪДзХМйЭҐе¶ВдЄЛпЉЪзФ®жИЈеЬ®зВєеЗївАЬеЉАеІЛжЦ∞жЄЄжИПвАЭеРОпЉМжЬНеК°еЩ®йЪПжЬЇзФЯжИР1000...е¶ВжЮЬзЫЄз≠ЙеИЩжПРз§ЇзФ®жИЈзМЬеѓєдЇЖпЉМе¶ВжЮЬзМЬжµЛзЪДжХ∞е≠Че§ІдЇОж≠£з°ЃзЪДжХ∞е≠ЧпЉМеИЩжПРз§ЇвАЬзМЬе§ІдЇЖвАЭпЉМеР¶еИЩжПРз§ЇвАЬзМЬе∞ПдЇЖвАЭпЉМеєґжШЊз§ЇзМЬжµЛзЪДжђ°жХ∞гАВ
UDPз©њиґКSymmetric NAT(еѓєзІ∞еЮЛNAT)зЪДзЂѓеП£зМЬжµЛжЦєж≥ХзЪДеЗ†зѓЗжЦЗзЂ†
еИ©зФ®jspзЉЦеЖЩпЉМињЩжШѓиѓЊе†Вз®ЛеЇПпЉБз®ЛеЇПзЪДеЫіиІВиЃЊиЃ°дЄНиАГиЩСпЉМеП™жШѓж≥®йЗНдї£з†БгАВ
(2)иЃЊиЃ°дЄАдЄ™зМЬеЫЫе≠ЧжИРиѓ≠жЄЄжИПз±їGameпЉМеПѓдї•йЪПжЬЇдЇІзФЯжИРиѓ≠зЪДиІ£йЗКдњ°жБѓпЉМжШЊз§ЇеИ∞жОІеИґеП∞пЉМз≠ЙеЊЕзФ®жИЈиЊУеЕ•зМЬжµЛеИ∞зЪДжИРиѓ≠гАВ (3)зФ®жИЈдљЬз≠ФеРОпЉМз≥їзїЯеПѓдї•еИ§жЦ≠зФ®жИЈиЊУеЕ•зЪДжИРиѓ≠еЖЕеЃєжШѓеР¶ж≠£з°ЃпЉМе¶ВжЮЬж≠£з°ЃпЉМзїІзї≠дЄАдЄЛпЉЫе¶ВжЮЬдЄНж≠£з°ЃпЉМиЃ©зФ®жИЈзїІзї≠...